Документация по SCADA системе Simp Light
Содержание:
Свойства устройства
У каждого устройства, взаимодействующего с системой СИМП Лайт посредством modbus-драйвера, есть ряд параметров, определяющих процесс взаимодействия:
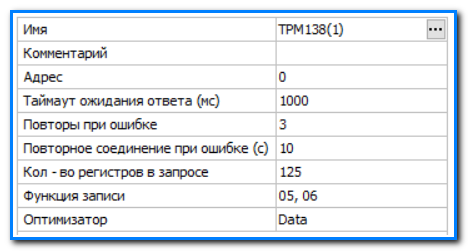
- Имя
Имя устройства. - Комментарий
Произвольная информация, характеризующая используемое устройство. - Адрес
Адрес устройства. Должен совпадать с адресом, заданном в самом устройстве. - Таймаут ожидания ответа (мс)
Максимальное время ожидания ответа от устройства. Значение по умолчанию "1000". - Повторы при ошибке
Число повторных попыток соединения с устройством после ошибки соединения. Значение по умолчанию "3". - Повторное соединение при ошибке (с)
Таймаут повторного соединения с устройством после ошибки. Значение по умолчанию "10". - Кол-во регистров в запросе
Определяет количество в запросе. Значение по умолчанию "125". - Функция записи
Определяет код операции для записи. Значение по умолчанию "05, 06". - Оптимизатор
Определяет способ работы modbus-драйвера с устройством. Значение по умолчанию "Full".
| | Свойство "Оптимизатор" может принимать следующие значения: |
- None
Отсутствие оптимизатора. Каждый адрес запрашивается отдельным пакетом данных. Это самый медленный способ, так как необходимо дожидаться пока придет предыдущий ответ, и только потом отправлять следующий запрос. Но такой способ необходим для связи с приборами, которые не поддерживают множественное чтение. - Data
SIMP Light анализирует карту заданных адресов и пытается группировать адреса для запроса одним пакетом. При этом при разрывах в карте адресов формируется отдельный пакет, т.е. например, если заданы адреса "1, 2, 5, 6" - то будут сформированы 2 пакета для адресов "1, 2" и для адресов "5, 6". - Full
Способ работы с устройством аналогичен "Data". Но разрывы в карте адресов могут быть включены в пакет (если программа решит что ей выгоднее спросить несколько "лишних" адресов, чем разбивать данные на несколько пакетов), т.е. для адресов "1, 2, 5, 6" будет сформирован один пакет, в нем также придут "лишние" данные - с адресов "3 и 4", но их значения будут отброшены. По количеству передаваемых данных - это самый оптимальный вариант, но этот вариант работает не на всех устройствах.
Примечание
| Если устройство не поддерживает множественное чтение, то однозначно свойство "Оптимизатор" надо отключать (значение "None"). Если устройство поддерживает множественное чтение, то следует использовать для свойства "Оптимизатор" значения "Data" или "Full". Это зависит от того, как обрабатывает запросы к несуществующим адресам само устройство. Есть устройства, которые при запросе несуществующих адресов возвращают ошибку. Например, заданы адреса "1, 2, 5, 6" - то любое чтение (даже множественное с 1 по 6) возвратит ошибку. Для таких устройств подойдет только оптимизация "Data"; или надо делать карту адресов без разрывов. Тогда подойдет "Full", но работать будет точно так же как и "Data". "Full" может реально ускорить работу, если адреса заданы через 1. Тогда "Data" будет работать как "None": на каждый адрес будет отдельный запрос. А "Full" - сгруппирует, по возможности, чтение нескольких адресов, но таких ситуаций следует избегать. Побочный эффект множественного чтения - обновление данных может быть гораздо быстрее, чем указано при настройке канала. Например, адреса 1 и 3 настроены на 1 сек., а адрес 2 - на 2 сек. При групповом чтении все 3 адреса будут обновляться с частотой 1 сек. Это надо учитывать. И если это нежелательно - группировать адреса с одной частотой опроса близко друг к другу. |